How I stopped fighting prompts and started building feedback loops


The weird thing about the internet is that it’s only possible because of one weird maths fact.
That is; some operations are expensive to do, but cheap to check. Factoring a huge number into two primes is hard, but multiplying those primes back together and verifying you got the original number is easy.
We’ve been able to use this asymmetry to our advantage. We’ve built security infrastructure on top of this because we can instantly and cheaply verify a claim, even if producing the claim was costly.
So, what does asymmetric operations have to do with AI?
Prompt engineering as a discipline is a practice of attempting to find the best input token or vector that, when passed into a generation run, results in a magic set of outputs.
In fact, you could probably spend your whole life like a monkey on a typewriter, searching incessantly for this one magic set of words.
In my situation, I kept getting burned by “simple” prompt tweaks that felt like they should work. I would add one more constraint, then one more, then one more, but just end up back where I started.
Even though the magic words were hard to find, the failures in the outputs were quite easy to find.
The model would add a forbidden word or phrase, or skip step 7 of a 14 step SOP (or step one 🤦), or change a variable name halfway through, or slip in the exact punctuation style I told it not to use.
The frustrating part was that spotting the failure was trivial. I could read the output and find the problem in three seconds. The hard part was getting the model to not do it in the first place, without turning the prompt into a legal document.
In fact, I also realised that for other LLMs, spotting that failure is also trivial. You can ask, within the same chat, in the next conversation turn, for the AI to self review itself. And it would find its own mistakes.
That is when the asymmetry clicked for me. Generation is the hard problem. Evaluation is often the easy problem.
Prompt engineering tries to solve the hard problem by squeezing it into the generation step. You’re asking for a clean output while also asking the model to be its own QA department, in one shot, with no feedback loop.
Sometimes it works, and sometimes it fails in the same dumb way for weeks.
So I stopped trying to treat the model like a function that returns the right answer if I find the magic words...
(next to try on my list - Please, for the love of god don’t output an em dash!!!)
... and I started treating it like a multi step process.
The agent can produce a draft fast, but it needs a reviewer who is allowed to be picky. That is where the generate, evaluate, revise pattern comes from.
You generate a first pass. Then you evaluate it against concrete acceptance criteria using an llm-as-judge. Then you revise using the evaluation as scoped feedback. Ideally use the RED pattern, which I talked about in a previous newsletter article.
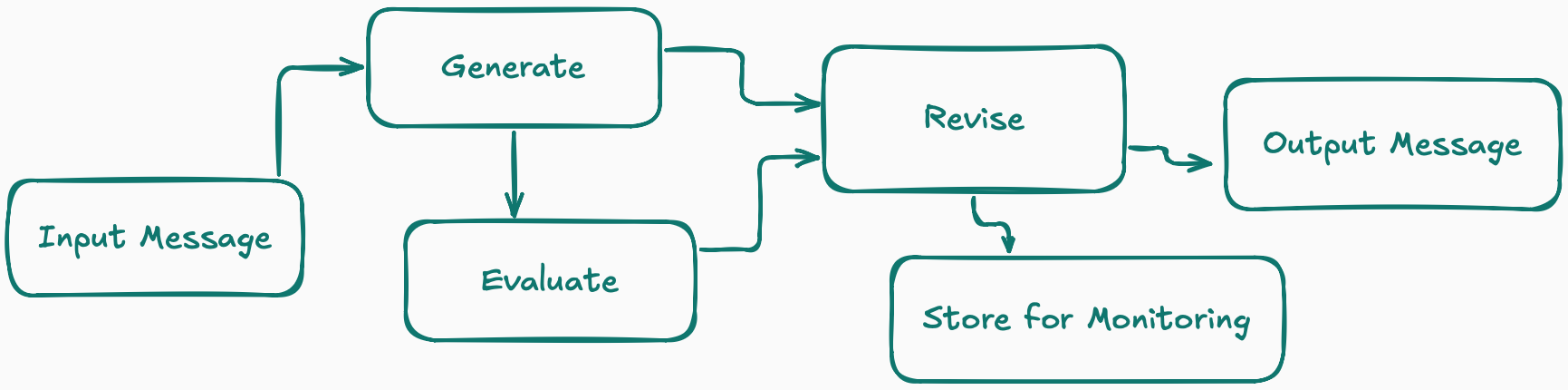
The key is that the evaluator is not there to “be smart.” It's there to be strict and small minded.
“Did the output include all required fields, avoid the forbidden tokens, follow the procedure, and not leak the secret?”
Evaluation guided revision works because it creates a narrow target.
“You used a banned phrase, and by the way, here is exactly where...” is actionable.
“This uses incorrect vocabulary.” (without giving citations) is not actionable.
It also changes how you write prompts. Instead of stuffing every rule into generation, you move a bunch of the strictness into the evaluator where strictness belongs. You let generation breathe, then you enforce reality with checks.
The evaluator feedback has to be shaped so the revision step can use it. I like feedback that looks like a diff request from a code review: exact failures, evidence quotes, and a pass or fail decision.

By doing this, another pro is that you can measure it. Once you have an evaluator, you can track pass rate, token cost per passing output, and what failures keep coming back.
So the pattern is really generate, evaluate, revise, evaluate. In fact, you can loop this process multiple times until you get one that passes all your evals.

If you've spent hours trying to prompt a model into never making a certain mistake, this is the key.
Stop betting everything on generation behaving deterministically. Build cheap verification, then use it to steer revisions like you would steer any system that is allowed to be wrong halfway, but not allowed to be wrong at the end.
Once you see it, you start noticing where your system already does this. Tests, type checks, linting, migrations with validations, canary deploys. AI isn’t special here, it's just less polite about reminding you that you needed a checker all along.



