Inference Options for Hosting a Sovereign Voice AI Stack in Australia


I spent some time recently trying to answer a specific question:
Can you run a production-grade voice AI inference stack on Australian sovereign hardware, and what does that actually look like in practice?
For this article, I'm focusing specifically on inference, instead of the STT or TTS components of the pipeline.
The two metrics that I believe are most critical for voice AI specifically are time to first token (TTFT) and throughput.
Voice pipelines feed LLM output into a TTS synthesiser sentence by sentence, so every millisecond of TTFT compounds across a real conversation.
If TTFT is too high or throughput too low, the voice output seems laggy and users notice immediately.
What I wanted to map out was which models are worth running, what hardware you actually need, and where you'd be able to source that in Australia.
Here is what I found.
The first thing to clarify is what "sovereign" actually means in practice, because it isn't easily defined.
I'd say there are two basic levels.
The first is just having the hardware physically in Australia, which you can achieve through AWS, GCP, or Azure through their over east or central Australian regions.
But those providers are often American companies, which means they fall under US law, and a US federal agency can request access to your data regardless of where the server physically sits.
This is a different risk profile from using a provider incorporated under Australian law with hardware in an Australian data centre.
The level of sovereignty you need depends entirely on the industry and the risk appetite of whoever is running the system.
A general SaaS product probably doesn't need the most restrictive tier.
For defence, health, or critical infrastructure, this is a real consideration.

Once I had that framing in place, I started looking at the model candidates for a 120B-class deployment.
The three that came up consistently were GPT-OSS-120B, Qwen 3.5-122B, and Nemotron 3 Super.
GPT-OSS-120B is the one I see most in the wild right now, with 5.1 billion active parameters, a 131K token context window, and broad provider availability.[^3]
Qwen 3.5-122B has around 10 billion active parameters and a 262K context window, and it seems promising on paper.[^3]
Nemotron 3 Super has 12.7 billion active parameters and a context window of 1 million tokens.[^2][^3]
Each of them is a 120B-class model, but I quickly found out they are not interchangeable.
| Model | Active params | Context window | Key voice AI weakness |
|---|---|---|---|
| GPT-OSS-120B | 5.1B | 131K tokens | Smallest context window of the three |
| Qwen 3.5-122B | 10B | 262K tokens | Extreme verbosity blows out latency |
| Nemotron 3 Super | 12.7B | 1M tokens | Prefill caching still maturing in vLLM |
Qwen was the first one I ruled out, and the reason was verbosity.
When I looked at the benchmark data, the industry median for similar tasks generates around 7.3 million tokens, while Qwen was generating 91 million.[^3]
That is over 12 times the output for equivalent work, and for a voice pipeline that is a hard blocker.
You are paying for tokens nobody asked for, latency blows out, and the TTS synthesiser downstream gets fed far more text than it was built to handle.
I couldn't find a clean way to suppress it when prompting in English, and while there is an open question about whether Mandarin prompting normalises it, I wouldn't bet a production system on that.
I crossed Qwen off and moved on.

That left GPT-OSS-120B and Nemotron, and that is where things got more interesting.
My recommendation ended up being Nemotron 3 Super, and here's why I landed there.
The theoretical 1 million token context window is large and useful for agentic conversation, and the TTFT figures are competitive with what I was seeing for GPT-OSS-120B.
GPT-OSS-120B has more community support right now and more providers carrying it, which is not nothing.
The part that tipped it for me was the hardware roadmap: Nemotron is built to run on both current H100 hardware and the newer Blackwell generation, which means your model choice remains valid on next-generation hardware without re-evaluation.[^2]
My approach would be to start with Nemotron and only fall back to GPT-OSS-120B if you hit blockers.
The model that scales with hardware upgrades without extra work from you is almost always the right default for a long-term stack.

For hardware, I landed on 8x H100 as the target for a PoC.
A 120B FP8 model needs roughly 120GB to 140GB just for the weights before you account for KV cache, and 8x H100 80GB gives you a 640GB VRAM envelope with enough room to work.[^3]

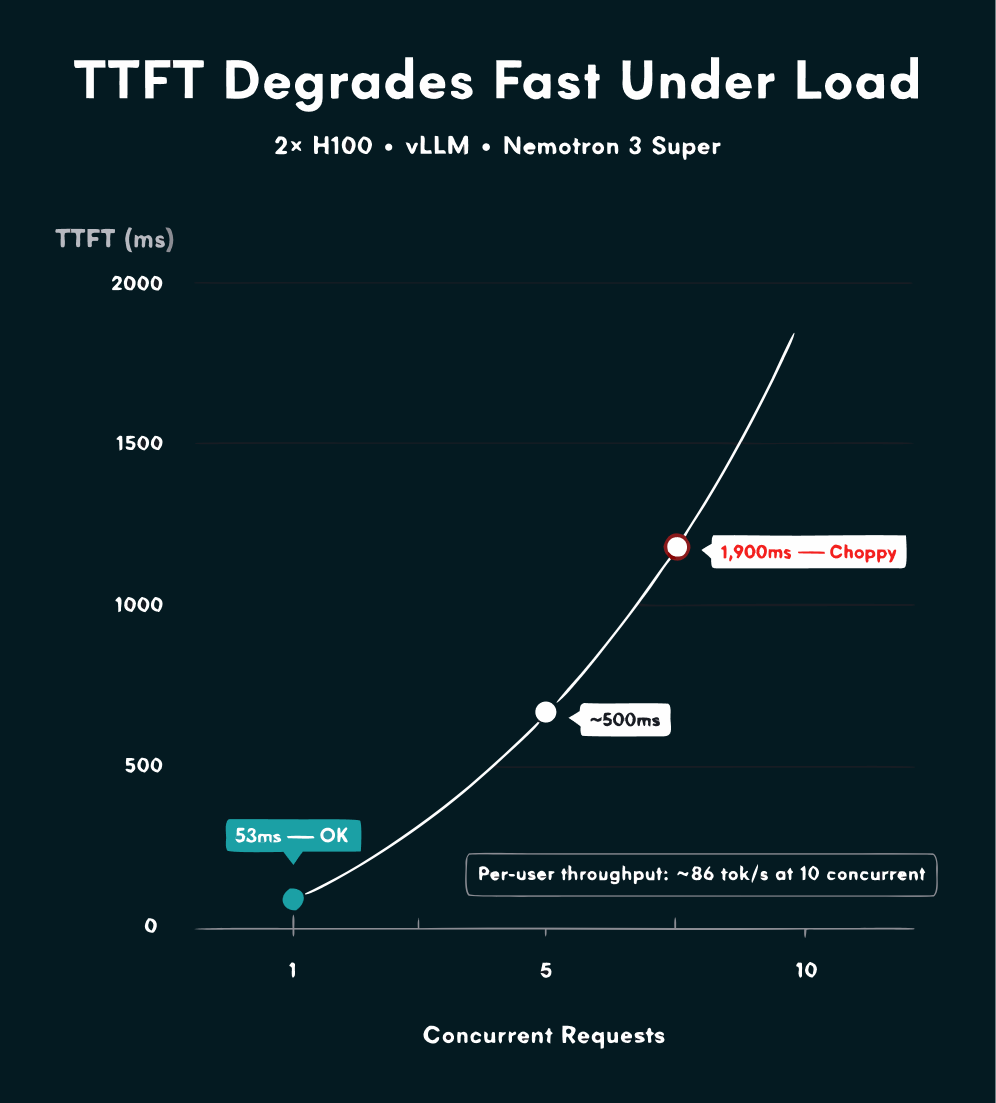
The concurrency numbers were the thing that surprised me most when I went through the inference benchmarks.
The best available data is from Clarifai's benchmarks of GPT-OSS-120B on 2x H100, which I'm using as a proxy for planning.[^1]
| Concurrency | TTFT (vLLM) | Total throughput (vLLM) | Per-stream |
|---|---|---|---|
| 1 | 53ms | 187 tok/s | 187 tok/s |
| 10 | 1.9s | 863 tok/s | ~86 tok/s |
| 50 | 7.5s | 2,212 tok/s | ~44 tok/s |
On 2x H100 with vLLM at a single concurrent request, you're looking at around 53ms TTFT and 187 tok/s, both acceptable for a voice workflow.
At 10 concurrent requests, TTFT jumps to around 1.9 seconds and total throughput rises to 863 tok/s across all instances, which works out to only about 86 tok/s per stream.
Those benchmarks were on 2x H100, so 8x should give more headroom, but the concurrency degradation pattern will still be there.
I would plan for no more than 10 concurrent sessions per node and scale horizontally if more capacity is needed.
For where to actually host it in Australia, I found the options split into two groups.
If a US-headquartered provider with an Australian region is acceptable for your sovereignty level, GCP, AWS, and Azure are all viable and the easiest to stand up quickly.
If you need an Australian provider, Sharon AI has an on-demand GPU dashboard with H100s listed at around USD 2.29 per GPU per hour, putting an 8-GPU node at roughly AUD 28 to 30 per hour at current exchange rates.[^4]
A 24-hour PoC on that stack comes to around AUD 700, or less if you scope it to a 6 to 12 hour window.
And for inference, I would start with vLLM over SGLang, because SGLang has better benchmark numbers in some concurrency tests but has known stability issues and tends to lag on new model support.[^1][^3]
Get your baseline running with vLLM first, then trial SGLang once you have real numbers to compare against.
The targets I would use: under 100ms TTFT at a concurrency of 1, and around 100 tok/s per user at a concurrency of 10.
[^1]: Clarifai. (2025, August 29). Comparing SGLang, vLLM, and TensorRT-LLM with GPT-OSS-120B. https://www.clarifai.com/blog/comparing-sglang-vllm-and-tensorrt-llm-with-gpt-oss-120b
[^2]: NVIDIA Nemotron Team. (2026, March 11). Run Highly Efficient and Accurate Multi-Agent AI with NVIDIA Nemotron 3 Super Using vLLM. vLLM Blog. https://vllm.ai/blog/nemotron-3-super
[^3]: Sovereign LLM Deployment Research Report. (2026, March 27). Internal research document. Covers model specs, Qwen verbosity benchmarks, VRAM requirements, and inference stack analysis for 120B-class models in an Australian sovereign context.
[^4]: Strategic Analysis of NVIDIA Cloud Functions and Sovereign GPU Infrastructure for Australian AI Deployment. (2026, March 27). Internal research document. Covers Australian GPU provider landscape, Sharon AI pricing, and sovereignty compliance considerations.



