Dumping Your Whole Codebase into an LLM - Introducing Dumb As Fuck Coding (DAFC) "The Fuck?"
👀 👉 Find the repo here: dafc
So, Gemini 2.5 Pro dropped with its massive one million token context window (yeah, I jumped on the 2.5 Pro bandwagon via OpenRouter pretty much instantly). And it hit me: gone are the days of meticulously picking files with tools like Cursor or Windsor. Now, you can just dump your entire codebase into the context, right? Well, kinda.
To make this work, I built a little tool and a methodology I call Dumb as Fuck Coding, or "DAFC (The Fuck?)" for short. The idea is simple: feed your whole project's code to an LLM and start asking questions or demanding features. This works brilliantly, provided your codebase stays within certain limits.
My Dumb As Fuck Coding Rules
I mentioned these on X before, but here are the core rules I live by for this approach:
- Max 500 Lines Per File: Seriously. If a file gets bigger, break it down. Keeps things manageable.
- Max ~50 Files (Aim for ~10): Limits the overall scope. Forces modularity.
- Max 5 Database Tables (Aim for 3, excluding users): Keeps the data model simple. If you need more, it's probably a separate micro-API.
Why These Rules? It's About One-Shotting the LLM
Okay, why these specific numbers? It boils down to a few things:
- Lowering Tokens & Complexity: Keeping files small and few reduces the total tokens shoved into the LLM. This drastically increases the chance you'll get a good, complete answer in one shot. Whether you're using Gemini 2.5 Pro, 4o, or even Claude, hitting these constraints makes them way more reliable.
- Reducing Cognitive Load: If you have to jump in and debug, you're not wading through 3,000-line monsters. Smaller files = easier understanding.
- Forcing Modularity: These limits basically force you into a more modular architecture from the get-go. The AI handles the boilerplate if you give it these constraints.
- Enabling Orchestration: Small, self-contained projects are perfect for hooking together later with tools like Zapier or n8n. You're essentially building micro-APIs by default.
- Finishing Faster & Safer: My goal is to get a functional micro-app done within maybe 3 days of back-and-forth prompting. Any longer, and hallucinations creep in. Keeping things small means the final security/performance audit you ask the LLM to run is actually somewhat trustworthy because the scope is contained. You could even enforce this with a pre-commit linter.
"The Fuck?" Tool Explained
So, how does the DAFC tool actually work? It's basically two parts:
- Context Gatherer: This script spiders through your project directory. It respects
.gitignoreand a custom.dafcignorefile, grabs all relevant files based on extensions (like.ts,.tsx,.sql, etc.), notes the relative path and line count, and bundles the content using Markdown or XML formatting. - LLM Interfacer: This takes the generated context blob, sticks it at the beginning of your prompt, and sends it off. I usually run it like this:
dafc "My query here, like: I want to improve the appearance of the top bar using my theme. How?".
I'm using OpenRouter mainly because their free tier for Gemini is pretty generous. It's rate-limited by resource contention, seems like – you just get blocked if it's busy. My script has an exponential backoff retry (up to 5 times), so you eventually get the streaming response.
The tool dumps the LLM's output into response.md in the same directory. You can open this in VS Code, Cursor, whatever, and either copy-paste the full files (remember, max 500 lines!) or just read the explanation.
I augment how it responds through a .dafcr file. Here's an example: .dafcr. I even throw in a visual design brief for wagn.ai to get outputs matching my aesthetic.
Here's the repo: dafc
And here's a rough diagram of the flow:
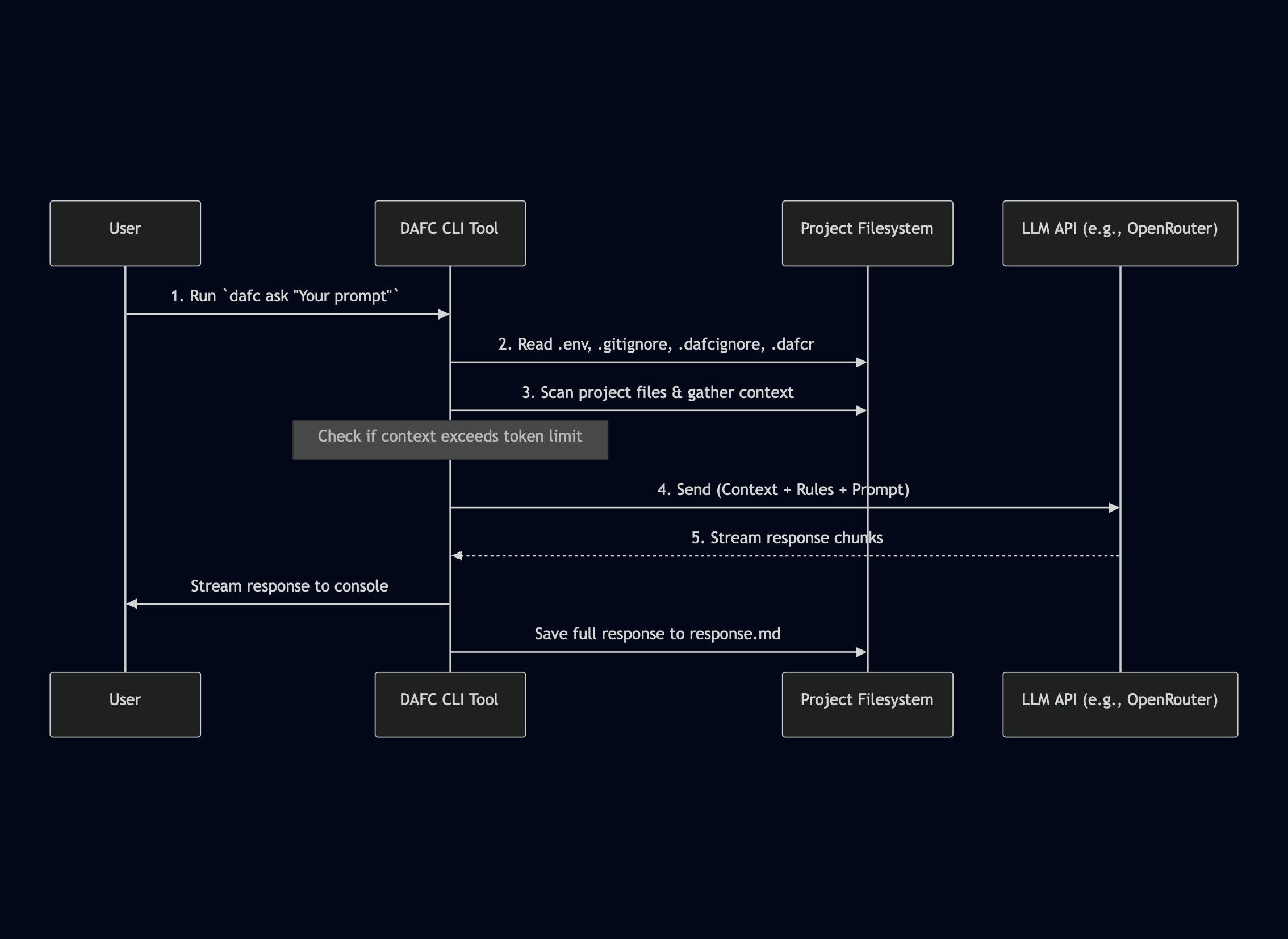
Building Big Things Small: The Micro-API Strategy
The key to building something bigger than a tiny side project with DAFC is don't. Instead, build lots of small DAFC projects (micro-APIs) and stitch them together.
Think about a basic e-commerce site. You start listing tables: Users, Products, Suppliers, Sales, ShoppingCarts, Discounts, Clients (maybe B2B?), Companies, Employees, Reviews, ChatLogs... boom, you're easily past 10 tables.
With the DAFC rule (aim for 3 tables/API), you'd split this up:
- Product API: Manages
Products,Discounts,Reviews. Handles product display logic. - User/Order API: Manages
Users,ShoppingCarts,Sales. Handles the customer-facing checkout flow. - Backend/Supplier API: Manages
Suppliers,Clients(B2B),Companies,Employees. Handles the backend/wholesale stuff.
Now you have three distinct micro-APIs, each manageable under DAFC rules. You can then use Zapier or n8n (or maybe a dedicated gateway API you build) to orchestrate workflows between them. Need to check inventory when a user adds to cart? Zapier calls the Product API, then the User API. Easy peasy. It also gives you, the integrator or subject matter expert, a clean high-level view in the Zapier/n8n interface.
Protect your APIs with API Keys or OAuth if they're public-facing (like on cloud Zapier/n8n). If it's all internal on a private server/VPN, maybe less critical.
I'll probably write a more detailed post on this specific example later.
My End-to-End DAFC Workflow
So what does building a single micro-API look like day-to-day?
- Visualize First (Vibe Coding): I actually like starting with visual tools.
v0.devis great if you have a consistent theme prompt.bolt.neworlovable.aiwork too. Ask for a stateless application, just the UI components. Play around until it looks right. This might take a day or two, depending on rate limits. - Download & Setup: Grab the code from v0/Bolt. Get it running locally. If you're unsure how, ask
the fuck?tool!dafc "I don't know how to run this, pls help" - Implement Logic with DAFC:
- Describe the logic needed for a feature concisely. I use Super Whisper and just word vomit for a couple of minutes about what needs to happen.
- Feed this description + the full codebase context (via the DAFC tool) to Gemini.
- Get back the full, modified files. Because files are small (max 500 lines), reviewing and copy-pasting is easy. I always ask for Markdown output where files are in code blocks. Here are some example outputs.
- Repeat for each feature/change. Keep zero chat history – always send the full context for single-shot changes. This avoids context drift, though it means re-uploading. Since I'm hands-on and it's collaborative, this works better for me than pure voice coding where context might get stale.
- My Preferred Stack: I always ask the LLM to start with Vite + React + TypeScript. If I need a backend, it's Express + TypeScript using Bun, with SQLite for the database (perfectly fine for small, specific projects). Static hosting capability is key.
- Testing & Audits: Once the core logic is there, ask Gemini to write unit tests, and importantly, run a security audit and a performance audit. Crucial steps often missed in rapid 'vibe coding'.
- Deploy:
- Frontend/Static: Cloudflare Pages/Wrangler. It's free, hooks up easily with domains on Cloudflare (which you should be using anyway). You can deploy in under an hour.
- Backend: If you need an Express backend:
- Ask
the fuckto generate aDockerfileand maybe a simple deployment bash script. - Deploy to a cheap VM on DigitalOcean, Fly.io, etc. (~$10/month).
- Ask
Beyond Code Gen: Asking Questions & Getting Diagrams
Even if you don't have the LLM write all the code, DAFC is amazing for just understanding a codebase. Upload the whole thing and ask:
- "Where is the logic for user authentication?"
- "Generate a TODO list for implementing feature X."
- "Create an architecture diagram in Mermaid.js for this system." Here's an example I made:
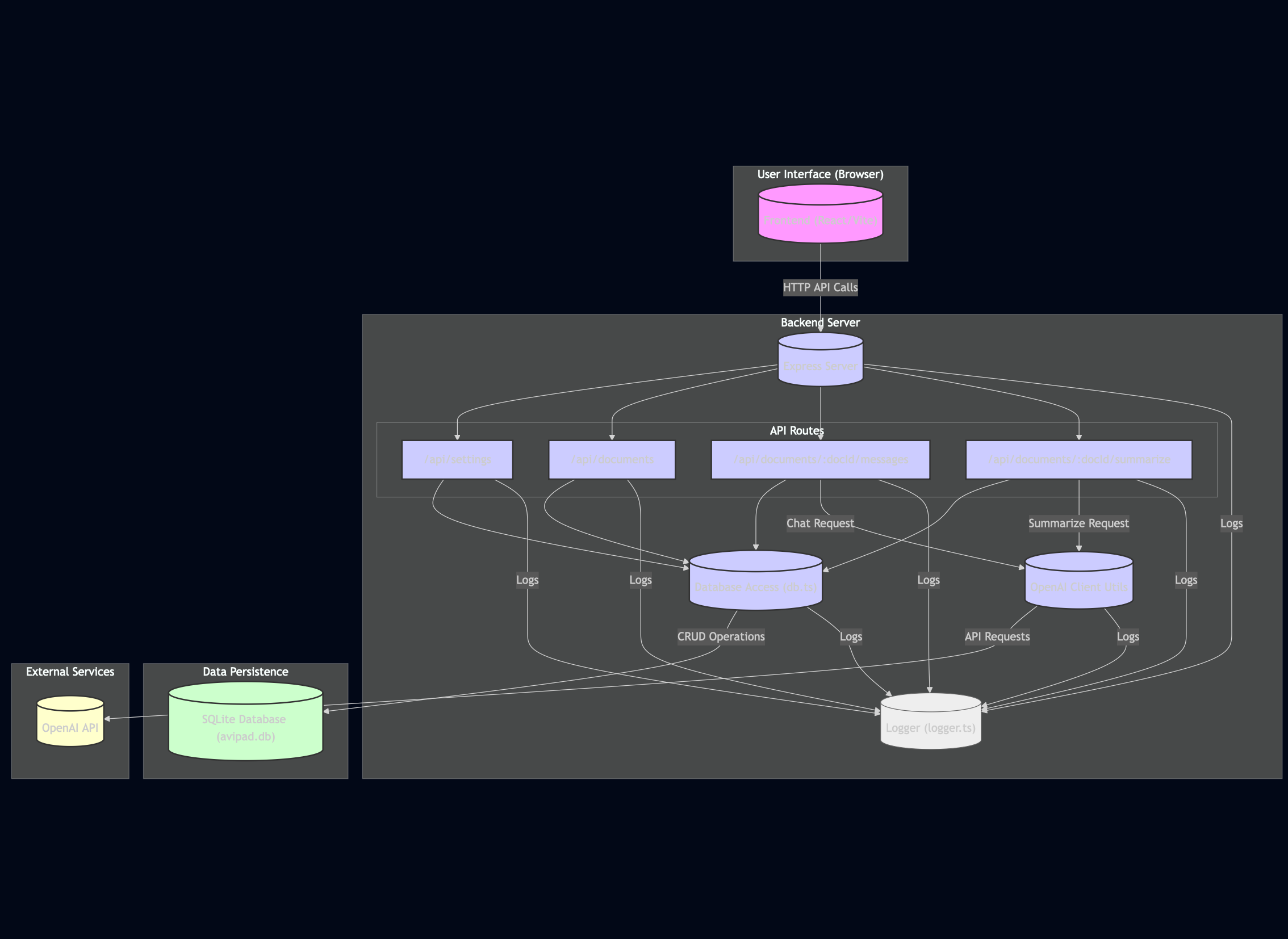
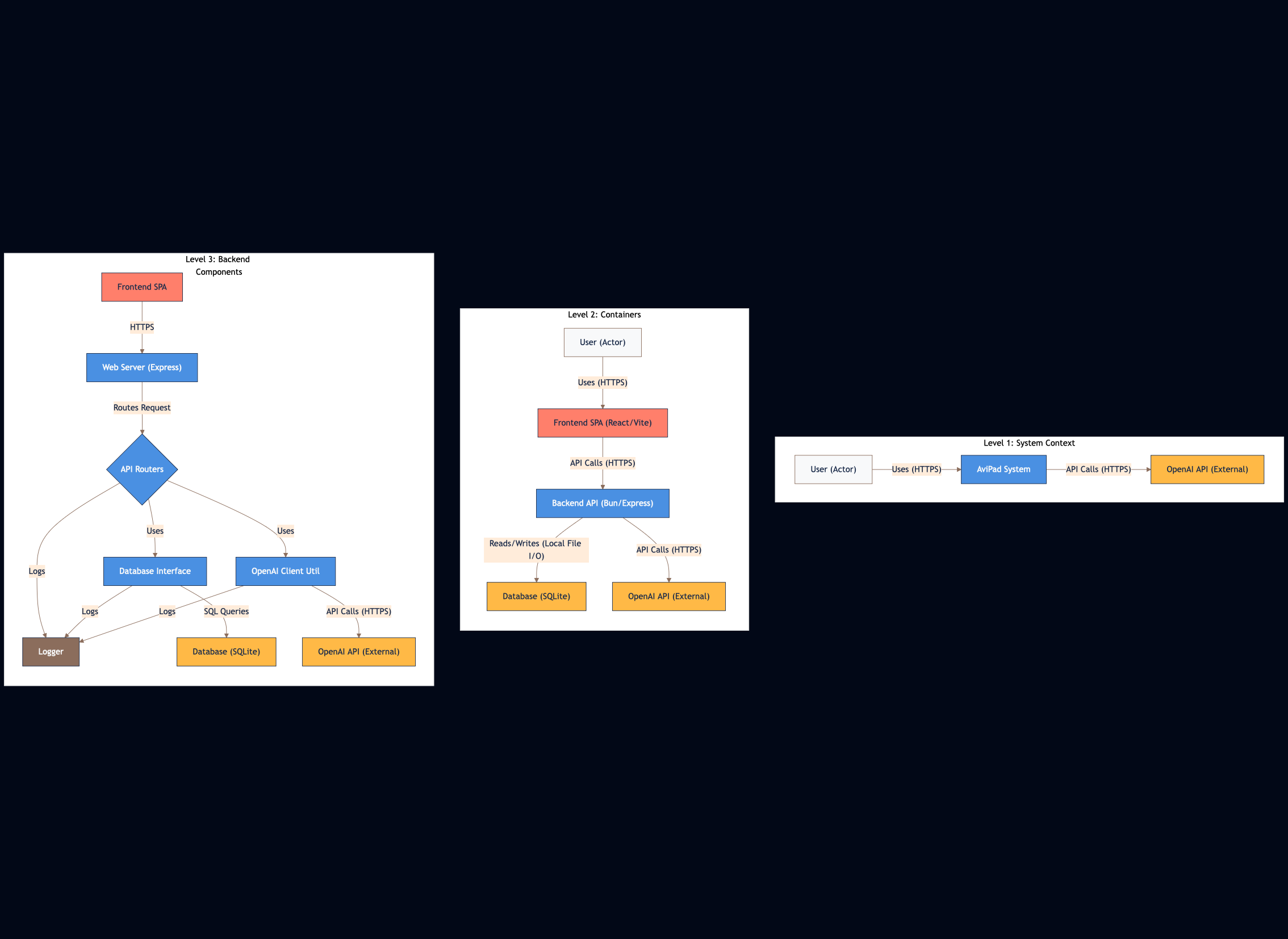
- "Generate a C4 model context diagram (C1) based on the code." If you include your Product Requirements Doc (PRD) in the context, it might even manage a System Context diagram (C0). Example:
Okay, What Are the Downsides? (Limitations of DAFC)
Look, this isn't a silver bullet. DAFC has limits:
- Legacy / Massive Codebases: Forget it. If you have a huge, old monolith, DAFC isn't practical. You're better off building a RAG pipeline (indexing files, generating summaries) but that's a whole other world of pain – keeping summaries up-to-date, handling new files, etc. Generating context on-the-fly like DAFC avoids this, but only works for small projects.
- Deep Domain Complexity / Ambiguous Terms: If your codebase uses the same word (like "customer") to mean different things in different contexts (B2B client vs B2C user vs support ticket requester), the LLM will get confused. You'd need to dive into advanced concepts like canonical representation to sort that out. I wrote about that in Canonical Naming. DAFC will likely fall apart here.
- Large Teams: DAFC is mostly a solo / very small team approach. If coordinating this across many developers, still use PRs.
- Highly Sensitive Data IN the Codebase: First off, don't do this. Secrets belong in
.envfiles or proper secret managers. But if for some insane reason you have sensitive stuff hardcoded, do not upload your codebase to an external LLM. Period. You'd need to look into expensive local LLM setups ($10k+ hardware) but likely won't match Gemini's quality anyway. - Secrets / API Keys: My tool respects
.gitignoreby default, so.envfiles should be ignored. You can add more patterns to.dafcignore. Standard practice is: keep secrets out of your codebase and Git history. DAFC doesn't change that.
Wrapping Up
So, that's Dumb as Fuck Coding. It's a pragmatic way I've found to leverage these huge context window LLMs like Gemini 2.5/2.5 Pro today for building small, focused applications incredibly quickly. By setting strict constraints, you make the LLM more reliable, keep complexity down, and naturally fall into a micro-service-y architecture you can orchestrate easily.
If you're a software engineer wanting to get your feet wet with AI development without getting lost in complexity, give it a try. You might be surprised how fast you can build stuff. You can probably crank out three specific micro-apps in a day once you get the hang of it. Just keep it simple, keep it small, and let the LLM do the heavy lifting within those boundaries.