Options for Moving STT and TTS Pipelines to Australia in April 2026


If you're running a voice AI pipeline on Deepgram, AssemblyAI, or Cartesia out of US servers, and someone asks whether you can move it to the Australian jurisdiction, how would you answer?
I would say yes, you can, but your options will depend on your specific requirements.

Deepgram, AssemblyAI, and Cartesia are good products, and everybody and their mom knows it, but their Australian endpoints are enterprise-only right now, not self-serve.
That means if you're a small team, you can't just flip a region flag in your dashboard and call it done.
Instead, the practical path would be to go through AWS, Azure, or decide to host your own open-source models.
Which one you pick depends on how much sovereignty you will need.
Most private sector clients in resources or professional services are fine with cloud self-hosted.
The fastest path is managed APIs, if your clients don't have hard data residency requirements beyond the Privacy Act baseline.
AWS Transcribe and AWS Polly both have live endpoints in ap-southeast-2 (which is Sydney), and you can sign up and start calling them today with a standard AWS account.
Azure has equivalent speech services in Australia East if you're already in the Microsoft ecosystem.
The tradeoff is that these models are older generation, and the voice quality and expressiveness are noticeably worse than what the frontier STT and TTS models will produce.
If your users are already used to a more natural-sounding voice, they will notice immediately.
You may need to consider running an A/B test before committing, because that quality gap can affect adoption.
But if expressiveness isn't the core of your product, this path takes about two weeks to validate and costs almost nothing to stand up.

Cloud self-hosting is where most teams who need real control without the complexity of physical hardware should land.
You rent a GPU in an Australian AWS or Azure region, you deploy your own models, and you own the stack from the model weights down.
AWS has A10G instances in Sydney, and Azure has equivalent options in Australia East, both giving you around 24 gigabytes of VRAM which is enough to run a solid STT and TTS pair simultaneously.
For speech-to-text, the current best options are Whisper Large V3 Turbo if you want wide community support, or Cohere Transcribe if the community tooling has matured enough by the time you're reading this.
For text-to-speech, Kokoro is the clear recommendation for now: it's 82 million parameters, Apache 2.0 licensed, sub-150ms latency, and runs comfortably alongside your STT model on the same GPU.
STT options:
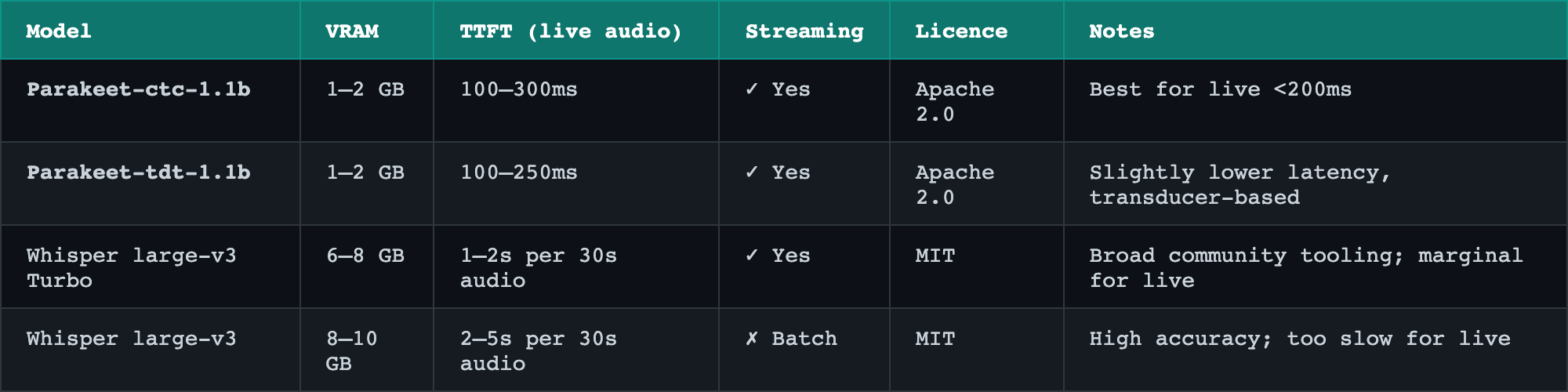
TTS options:

The recommended pair is Parakeet-ctc-1.1b and Kokoro-82M. Both Apache 2.0, both streaming, combined VRAM around 2 GB — fits on a T4, which is the cheapest GPU available in Sydney today.
Setting up your own self hosting takes one to two weeks of developer time to stand up, but satisfies most compliance requirements for private sector Australian clients.
You can hit sub-300 milliseconds for STT and TTS combined at both the managed API and cloud self-hosted tiers.
On managed API, AWS Transcribe and Polly together land around 300 to 400 milliseconds from Sydney, which is already close to the target and often good enough in practice.
On cloud self-hosted with an A10G or equivalent, running Parakeet and Kokoro on the same GPU, you can also get similar performance.
The real bottleneck in any live voice pipeline is the LLM sitting in the middle, not the STT or TTS on either side.
Shaving 50 milliseconds off your transcription step while your language model takes 800 milliseconds to respond is optimising the wrong thing.
Get the LLM latency under control first, then worry about squeezing the edges.
For most production systems, 300 milliseconds on STT + TTS is enough.
Colocation means you own or lease physical hardware sitting in an Australian data centre like NEXTDC's P1 or P2 facilities in Perth.
The data centre handles power, cooling, and physical security, but the hardware is yours and you are responsible for everything running on it.
An RTX 4090 is the baseline GPU recommendation here, giving you 24 gigabytes of VRAM and enough headroom for Whisper or Parakeet plus Kokoro at low concurrency.
If you need more headroom or are future-proofing toward a heavier LLM running on the same box, an RTX 6000 with 48 gigabytes is the step up.
This tier is the right call when a client needs hardware custody for audit purposes, is working toward a defence contract, or wants a clear path to air-gapped operation later without re-architecting.
Add about a month to your timeline compared to cloud self-hosted, because hardware procurement, shipping, and rack installation take real time.
Expect six weeks from decision to production if everything goes smoothly.
Air-gapped on-premise puts the machine on your own site with no internet connection.
This may be the answer for defence-adjacent work, classified processing, or any engagement where data leaving the building is simply not allowed under the contract or the law.
The same RTX 4090 or 6000 recommendation applies, and the same open-source model stack runs fine in a fully offline environment once the weights are loaded locally.
What people often underestimate is model updates: without internet access, getting a new model version onto the machine requires a deliberate process involving physical media or a secure internal transfer mechanism.
You also lose the ability to pull community fixes or fine-tuned variants easily, so whatever you deploy needs to be stable and well-validated before it goes in.
Add two months to the colocation timeline for hardening, air-gap validation, and the operational procedures your client will need documented.
If you are migrating a live pipeline today, the practical sequence is straightforward.
Start by deciding whether your clients can accept the expressiveness tradeoff of the AWS or Azure managed models, because if they can, you can be live in two weeks with zero hardware to manage.
If they can't accept that tradeoff, or if you anticipate needing fine-tuned voices or custom accents down the track, go straight to cloud self-hosted on an A10G in Sydney and deploy Kokoro plus Whisper Large V3 Turbo or Cohere Transcribe.
If a client asks about colocation or air-gap, the question to ask them back is whether they have a specific compliance obligation that mandates it, not whether they feel better about owning the hardware.
Most of the time the answer is no, and cloud self-hosted satisfies their actual legal position.



